2 - Algorithms used
The application includes functions for various tasks, including data cleaning, creating baseline predictions, utilizing machine learning (ML) for predictions, computing metrics, and generating a dataset for displaying the predictions.
The clean_data function manages the job of cleaning the initial dataset. It achieves this by transforming
the 'Date' column into a datetime format. This function takes an initial DataFrame as input
and delivers a cleaned copy of that DataFrame as its output.
def clean_data(initial_dataset: pd.DataFrame):
print(" Cleaning data")
initial_dataset['Date'] = pd.to_datetime(initial_dataset['Date'])
cleaned_dataset = initial_dataset.copy()
return cleaned_dataset
Predictions:¶
predict_baseline() and predict_ml() returns prediction values from the cleaned
DataFrame (cleaned_dataset), the number of predictions to make (n_predictions), a
specific date (day), and a maximum capacity value (max_capacity).
Initially, they select the training dataset up to the specified date. Following that, they carry out specific calculations or adjustments to generate predictions. It's important to ensure that these predictions do not exceed the maximum limit.
def predict_baseline(cleaned_dataset: pd.DataFrame, n_predictions: int, day: dt.datetime, max_capacity: int):
print(" Predicting baseline")
train_dataset = cleaned_dataset[cleaned_dataset['Date'] < day]
predictions = train_dataset['Value'][-n_predictions:].reset_index(drop=True)
predictions = predictions.apply(lambda x: min(x, max_capacity))
return predictions
# This is the function that will be used by the task
def predict_ml(cleaned_dataset: pd.DataFrame, n_predictions: int, day: dt.datetime, max_capacity: int):
print(" Predicting with ML")
# Select the train data
train_dataset = cleaned_dataset[cleaned_dataset["Date"] < day]
# Fit the AutoRegressive model
model = AutoReg(train_dataset["Value"], lags=7).fit()
# Get the n_predictions forecasts
predictions = model.forecast(n_predictions).reset_index(drop=True)
predictions = predictions.apply(lambda x: min(x, max_capacity))
return predictions
compute_metrics() calculates some metrics about the predictions.
def compute_metrics(historical_data, predicted_data):
historical_to_compare = historical_data[-len(predicted_data):]['Value']
rmse = mean_squared_error(historical_to_compare, predicted_data)
mae = mean_absolute_error(historical_to_compare, predicted_data)
return rmse, mae
Output dataset¶
create_predictions_dataset() creates a predictions dataset for visualization purposes. It
takes:
-
the predicted baseline values (predictions_baseline),
-
ML predicted values (predictions_ml),
-
a specific date (day), the number of predictions to make (n_predictions),
-
and the cleaned dataset (cleaned_data).
The function returns a DataFrame containing the date, historical values, ML predicted values, and baseline predicted values.
def create_predictions_dataset(predictions_baseline, predictions_ml, day, n_predictions, cleaned_data):
print("Creating predictions dataset...")
...
predictions_dataset = pd.concat([
historical_data["Date"],
historical_data["Value"].rename("Historical values"),
create_series(predictions_ml, "Predicted values ML"),
create_series(predictions_baseline, "Predicted values Baseline")
], axis=1)
return predictions_dataset
Entire code¶
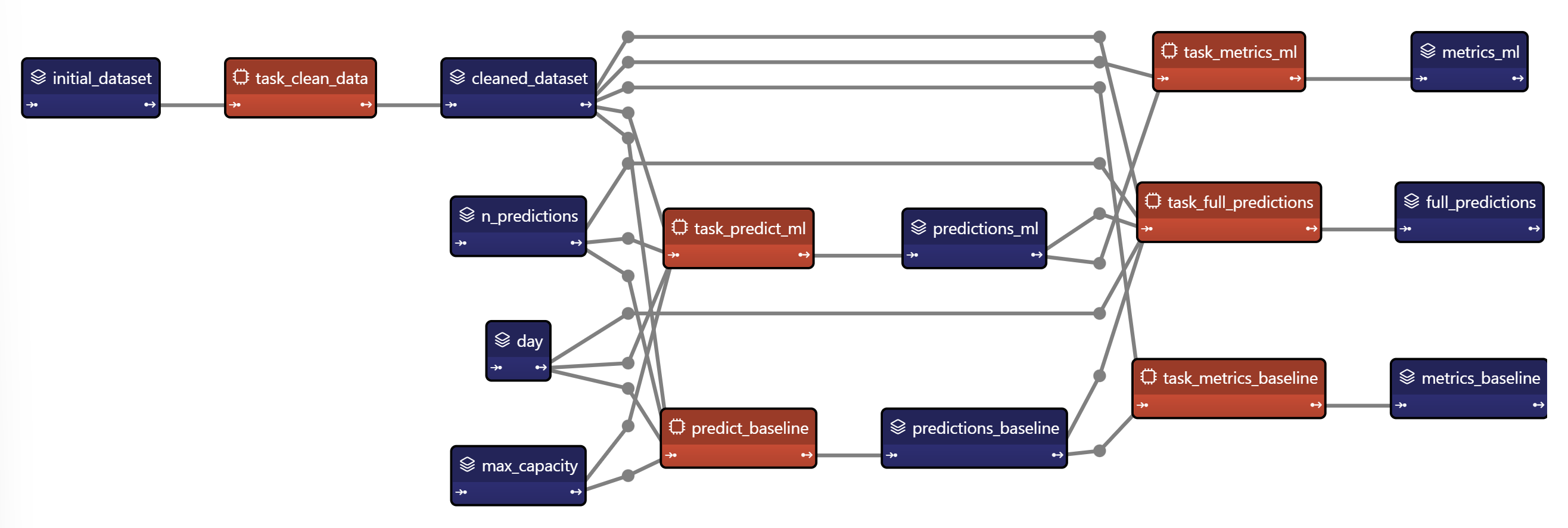
The following Python code corresponds to the algorithms/algorithms.py file. Chaining all the functions together can be represented as the following graph:
# For the sake of clarity, we have used an AutoRegressive model rather than a pure ML model such as:
# Random Forest, Linear Regression, LSTM, etc
from statsmodels.tsa.ar_model import AutoReg
import pandas as pd
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
import datetime as dt
def clean_data(initial_dataset: pd.DataFrame):
print(" Cleaning data")
# Convert the date column to datetime
initial_dataset['Date'] = pd.to_datetime(initial_dataset['Date'])
cleaned_dataset = initial_dataset.copy()
return cleaned_dataset
def predict_baseline(cleaned_dataset: pd.DataFrame, n_predictions: int, day: dt.datetime, max_capacity: int):
print(" Predicting baseline")
# Select the train data
train_dataset = cleaned_dataset[cleaned_dataset['Date'] < day]
predictions = train_dataset['Value'][-n_predictions:].reset_index(drop=True)
predictions = predictions.apply(lambda x: min(x, max_capacity))
return predictions
# This is the function that will be used by the task
def predict_ml(cleaned_dataset: pd.DataFrame, n_predictions: int, day: dt.datetime, max_capacity: int):
print(" Predicting with ML")
# Select the train data
train_dataset = cleaned_dataset[cleaned_dataset["Date"] < day]
# Fit the AutoRegressive model
model = AutoReg(train_dataset["Value"], lags=7).fit()
# Get the n_predictions forecasts
predictions = model.forecast(n_predictions).reset_index(drop=True)
predictions = predictions.apply(lambda x: min(x, max_capacity))
return predictions
def compute_metrics(historical_data, predicted_data):
historical_to_compare = historical_data[-len(predicted_data):]['Value']
rmse = mean_squared_error(historical_to_compare, predicted_data)
mae = mean_absolute_error(historical_to_compare, predicted_data)
return rmse, mae
def create_predictions_dataset(predictions_baseline, predictions_ml, day, n_predictions, cleaned_data):
print("Creating predictions dataset...")
# Create the historical dataset that will be displayed
new_length = len(cleaned_data[cleaned_data["Date"] < day]) + n_predictions
historical_data = cleaned_data[:new_length].reset_index(drop=True)
create_series = lambda data, name: pd.Series([np.NaN] * (len(historical_data)), name=name).fillna({i: val for i, val in enumerate(data, len(historical_data)-n_predictions)})
predictions_dataset = pd.concat([
historical_data["Date"],
historical_data["Value"].rename("Historical values"),
create_series(predictions_ml, "Predicted values ML"),
create_series(predictions_baseline, "Predicted values Baseline")
], axis=1)
return predictions_dataset