5 - Python expressions in properties
Download Step 5 Download the entire code
For Notebooks
The Notebook is available here. In Taipy GUI, the process to execute a Jupyter Notebook is different from executing a Python Script.
As shown before, parameters and variables in Taipy are dynamic. The same applies for every type
of object, even data frames. Therefore, you can perform operations on data frames, and Taipy GUI
will show real-time results on the GUI. These changes occur through the = assignment like
state.xxx = yyy (state.text = "Example").
Any expression containing xxx in the Markdown will propagate the changes and reload related
elements. It can be simple charts or tables, but it can also be an expression like this:
"""
## Positive
<|{np.mean(dataframe["Score Pos"])}|text|>
## Neutral
<|{np.mean(dataframe["Score Neu"])}|text|>
## Negative
<|{np.mean(dataframe["Score Neg"])}|text|>
"""
tgb.text("## Positive", mode="md")
tgb.text("{np.mean(dataframe['Score Pos'])}")
tgb.text("## Neutral", mode="md")
tgb.text("{np.mean(dataframe['Score Neu'])}")
tgb.text("## Negative", mode="md")
tgb.text("{np.mean(dataframe['Score Neg'])}")
This kind of expression creates direct connections between visual elements without coding anything.
A use case for NLP - Part 1¶
The code for NLP is provided here, although it's not directly related to Taipy. It will come into play in Part 2 when we wrap a GUI around this NLP engine.
Before executing this step, you should have pip install torch and pip install transformers.
The model will be downloaded and utilized in this code snippet. Note that Torch is currently
only accessible for Python versions between 3.8 and 3.10.
If you encounter difficulties installing these packages, you can simply provide a dictionary of
random numbers as the output for the analyze_text(text) function.
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from scipy.special import softmax
MODEL = f"cardiffnlp/twitter-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
def analyze_text(text):
# Run for Roberta Model
encoded_text = tokenizer(text, return_tensors="pt")
output = model(**encoded_text)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
return {"Text": text,
"Score Pos": scores[2],
"Score Neu": scores[1],
"Score Neg": scores[0],
"Overall": scores[2]-scores[0]}
A use case for NLP - Part 2¶
The code below uses this concept to create metrics on the data frame generated.
import numpy as np
import pandas as pd
from taipy.gui import Gui, notify
text = "Original text"
dataframe = pd.DataFrame({"Text": [""],
"Score Pos": [0.33],
"Score Neu": [0.33],
"Score Neg": [0.33],
"Overall": [0]})
def local_callback(state):
notify(state, "Info", f"The text is: {state.text}", True)
temp = state.dataframe.copy()
scores = analyze_text(state.text)
temp.loc[len(temp)] = scores
state.dataframe = temp
state.text = ""
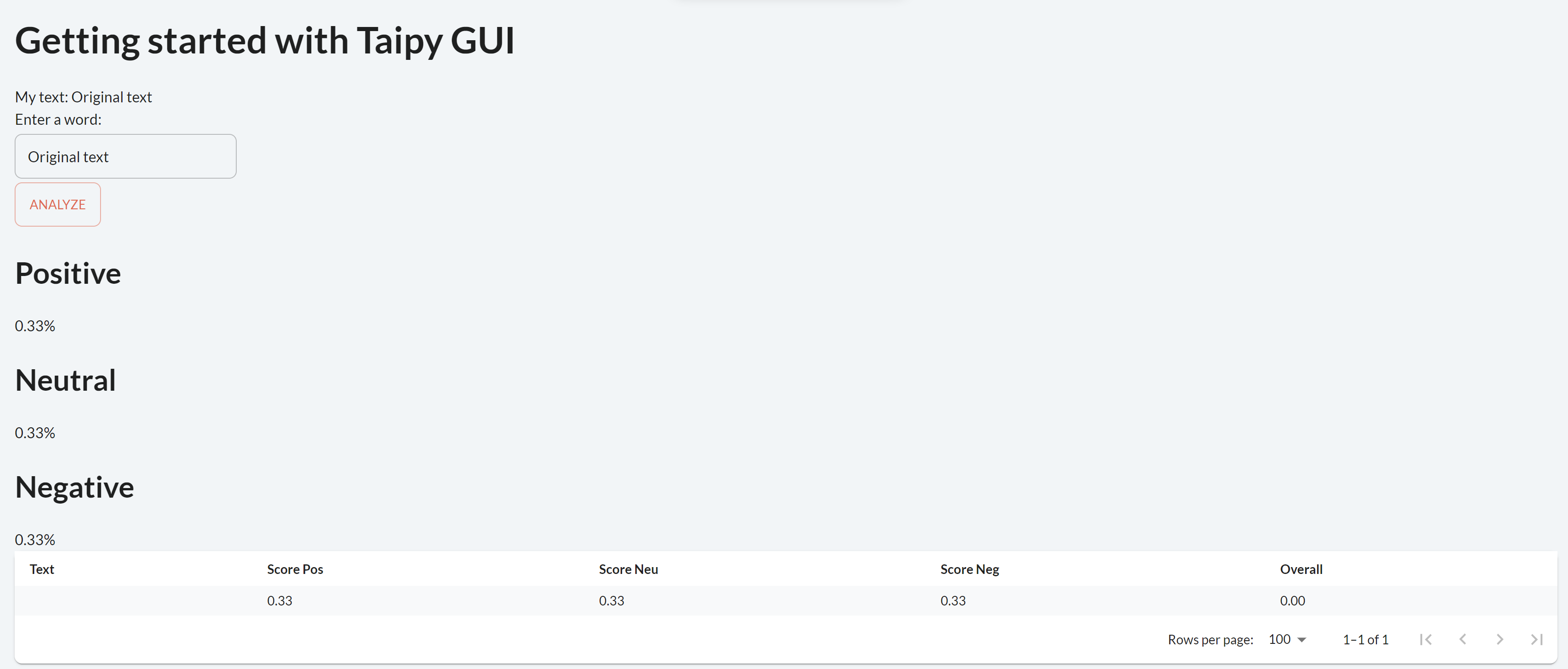
page = """
<|toggle|theme|>
# Getting started with Taipy GUI
My text: <|{text}|>
Enter a word:
<|{text}|input|>
<|Analyze|button|on_action=local_callback|>
## Positive
<|{np.mean(dataframe["Score Pos"])}|text|format=%.2f|>
## Neutral
<|{np.mean(dataframe["Score Neu"])}|text|format=%.2f|>
## Negative
<|{np.mean(dataframe["Score Neg"])}|text|format=%.2f|>
<|{dataframe}|table|>
<|{dataframe}|chart|type=bar|x=Text|y[1]=Score Pos|y[2]=Score Neu|y[3]=Score Neg|y[4]=Overall|color[1]=green|color[2]=grey|color[3]=red|type[4]=line|>
"""
Gui(page).run(debug=True)
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from scipy.special import softmax
import numpy as np
import pandas as pd
from taipy.gui import Gui, notify
import taipy.gui.builder as tgb
text = "Original text"
# Model setup
MODEL = "cardiffnlp/twitter-roberta-base-sentiment"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
# Initial dataframe
dataframe = pd.DataFrame({"Text":[''],
"Score Pos":[0.33],
"Score Neu":[0.33],
"Score Neg":[0.33],
"Overall":[0]})
def analyze_text(text):
# Run for Roberta Model
encoded_text = tokenizer(text, return_tensors='pt')
output = model(**encoded_text)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
return {"Text":text,
"Score Pos":scores[2],
"Score Neu":scores[1],
"Score Neg":scores[0],
"Overall":scores[2]-scores[0]}
def local_callback(state):
notify(state, 'info', f'The text is: {state.text}')
scores = analyze_text(state.text)
temp = state.dataframe.copy()
temp.loc[len(temp)] = scores
state.dataframe = temp
state.text = ""
# Definition of the page with tgb
with tgb.Page() as page:
tgb.toggle(theme=True)
tgb.text("# Getting started with Taipy GUI", mode="md")
tgb.text("My text: {text}")
tgb.input("{text}")
tgb.button("Analyze", on_action=local_callback)
# Displaying sentiment scores and overall sentiment
tgb.text("## Positive", mode="md")
tgb.text("{np.mean(dataframe['Score Pos'])}")
tgb.text("## Neutral", mode="md")
tgb.text("{np.mean(dataframe['Score Neu'])}")
tgb.text("## Negative", mode="md")
tgb.text("{np.mean(dataframe['Score Neg'])}")
tgb.table("{dataframe}", number_format="%.2f")
tgb.chart("{dataframe}", type="bar", x="Text",
y__1="Score Pos", y__2="Score Neu", y__3="Score Neg", y__4="Overall",
color__1="green", color__2="grey", color__3="red", type__4="line")
# Initialize the GUI with the updated dataframe
Gui(page, state={"dataframe": dataframe}).run(debug=True)